Ayuda
Lenguaje
Características generales del lenguaje.
[ Inicio ]
-
Case sensitive:
El compilador distingue entre minúsculas y mayúsculas.
-
Sentencias:
Cualquier sentencia debe acabar con el símbolo ';', a excepción de los símbolos
que cierran y abren grupos: '{' y '}'
-
Palabra vacía:
Se escribe dejando en blanco la parte derecha de una producción
-
Símbolo inicial:
Es el no terminal de la primera producción escrita en la gramática
-
Identificadores: La estructura de un identificador se corresponde con el de una secuencia
de números, letras o el símbolo '_'. Los identificadores no pueden comenzar con un número
y su longitud debe ser de uno como mínimo. Ejemplo de identificadores válidos:
gramática_1
__gramatica0001
OtraGramatica
_007
_0
Los únicos identificadores que no se pueden declarar son las palabras
reservadas, las cuales son las siguientes: analysis, grammar, global, terminal,
nonterminal, LL1, SLR1, LR1, LALR1.
-
Caracteres: Los terminales, además de identificadores, también pueden
ser caracteres. Estos sólo pueden ser caracteres ASCII y se escriben en la
gramática entre comillas simples. Los caracteres permitidos son:
'!' '#' '%' '&' '/' '(' ')' '=' '?' '^' '+' '-' '<' '>'
';' ',' '~' '.' ':' '|'
'{' '}' '*' '`' '[' ']' '\'' '\\'
Este tipo de símbolos, sólo puede ser de un único caracter, es decir que
símbolos del tipo:'>>' o '+=' no son válidos.
Para poner la comilla simple o la barra invertida hay que utilizar el caracter
de escape. Es decir: '\'' '\\'
Los caracteres alfabéticos, y numéricos (los componentes de los
identificadores), no se pueden poner entre comillas, ya que estos se pueden
poner directamente sin entrecomillar.
Este tipo de caracteres, sólo pueden ser terminales y además no hace
falta declararlos en la lista de terminales.
-
Los comentarios se pueden hacer de diversas formas:
Descripción EBNF del lenguaje
La descripción EBNF del lenguaje de entrada de PROLETOOL es la siguiente:
CUERPO_GLC ::= BLQ_GLOBAL LISTA_BLQ_LOCAL | LISTA_BLQ_LOCAL | DEF_LEXERS
BLQ_GLOBAL LISTA_BLQ_LOCAL | DEF_LEXERS LISTA_BLQ_LOCAL
DEF_LEXERS ::= DEF_LEXERS lexer id %{ DATOS_LEXER %} | lexer id %{ DATOS_LEXER %}
DATOS_LEXER ::= DATOS_LEXER simbolo | simbolo
BLQ_GLOBAL ::= global { CUERPO_GLOBAL }
CUERPO_GLOBAL ::= [DEC_ANALISIS] LISTA_DECLARACIONES LISTA_SENT_GLOBALES
DEC_ANALISIS ::= analysis TIPO_ANALISIS [; TIPO_ANALISIS] [;TIPO_ANALISIS] [;
TIPO_ANALISIS] ;
TIPO_ANALISIS ::= LL1 | SLR1 | LR1 | LALR1
LISTA_DECLARACIONES ::= LISTA_DECLARACIONES DEC_SIMBOLOS | DEF_USE_LEXER| EMPTY
DEF_USE_LEXER ::= use id ;
DEC_SIMBOLOS ::= DEC_TERMINAL | DEC_NO_TERMINAL
DEC_TERMINAL ::= terminal id {, id} ;
DEC_NO_TERMINAL ::= nonterminal id {, id} ;
LISTA_SENT_GLOBALES ::= {SENT_GRUPO}
SENT_GRUPO ::= id = { LISTA_SENT_PROD }
LISTA_SENT_PROD ::= {PRODUCCION}
PRODUCCION ::= id := LISTA_PARTE_DERECHA ;
LISTA_PARTE_DERECHA ::= PARTE_DERECHA {| PARTE_DERECHA}
PARTE_DERECHA ::= {SIMB_PARTE_DERECHA}
SIMB_PARTE_DERECHA ::= id
BLQS_LOCAL ::= DEC_LOCAL {DEC_LOCAL}
DEC_LOCAL ::= grammar id { CUERPO_LOCAL }
CUERPO_LOCAL ::= [DEC_ANALISIS] [DEC_SIMBOLOS] LISTA_SENT_LOCALES
LISTA_SENT_LOCALES ::= {SENT_LOCAL}
SENT_LOCAL ::= LISTA_SENT_PROD | INSTANCIACION_GRUPO
INSTANCIACION_GRUPO ::= id ;
EMPTY ::=
}
Estructura de un archivo válido
[ Inicio ]
Un archivo válido tiene dos secciones: parte global y parte local.
//- parte global-------------------------------
global {
// cuerpo global
}
//- fin parte global-------------------------------
//- parte local-------------------------------
grammar gram_1 {
// cuerpo global
}
grammar gram_2 {
// cuerpo global
}
// aqui se pueden poner mas gramaticas ...
//- fin parte local-------------------------------
La parte global es opcional pero debe haber como mínimo una gramática local
declarada. El contenido de la parte global y de las gramáticas locales va
encerrado entre corchetes.
Dentro del cuerpo de las declaraciones globales y gramáticas locales se puede
poner lo mismo a excepción de los grupos de producciones, que ya se explicará
en otro apartado.
En el cuerpo de la parte global lo primero que se pone es el tipo de análisis a
realizar, este se declara poniendo la palabra reservada
analysis seguida
de una lista con los análisis que se quiere realizar. Esta lista no puede ser
vacía y como máximo se pueden declarar 4 tipos de análisis. Ejemplo:
global {
// se ha elegido el analisis LL1 y LR1.
analysis LL1, LR1;
}
grammar gramatica_local {
analysis SLR1, LALR1;
}
La declaración del tipo de análisis sólo se puede hacer una vez (en cada
gramática o globalmente).
Además es opcional, si se quiere no hace falta ponerla, por defecto se
realizará un análisis LL1. Los tipos válidos de análisis son: LL1, SLR1, LR1,
LALR1.
Otro elemento que se puede declarar son los símbolos de las gramáticas, estos
pueden ser terminales y no terminales. La declaración de estos también es
opcional, no importa el orden en que se declaren, y esta si se puede repetir
varias veces.
global {
terminal a, b, c, d;
nonterminal A, J, P;
// no importa el orden y se puede poner mas de uno
nonterminal Uno, Dos, Tre;
terminal k, l;
}
Como se puede ver la declaración de terminales esta precedida de la palabra
reservada
'terminal', y los no terminales de la palabra
'nonterminal'.
Ejemplo resumen de la parte de declaraciones:
global {
analysis LL1, SLR1;
nonterminal A, J, P;
terminal a, b, c, d;
}
Resolución del ámbito de los símbolos.
[ Inicio ]
Todos los símbolos declarados globalmente, son accesibles desde todas las
gramáticas locales, es decir si se declaran globalmente no hace falta volver a
declararlos localmente. Lo que no se puede hacer es, en un mismo ambito definir dos
veces el mismo símbolo. Ejemplo:
global {
nonterminal A, B, C;
terminal a, b;
// no se puede declarar dos veces un símbolo esto seria erroneo
terminal a, B;
}
grammar gram_1
{
// no hace falta declarar A, a, b ya que estan declarados globalmente.
A := a b;
}
Si se declara un símbolo globalmente y este se vuelve a declarar localmente, no
pasa nada, tiene más prioridad el local. Claro si al declararlo de forma local
es del mismo tipo no pasa nada, pero si se declara localmente de un tipo
diferente al global tiene más precedencia el local. Ejemplo:
global
{
// en la parte global se declara como no terminal
nonterminal A;
}
grammar gram_1
{
nonterminal S;
// esta delaracion tiene mas prioridad que la global
// por lo tanto 'A' es un terminal.
terminal A;
S := A;
}
El nombre de una gramática es un símbolo global, si se vuelve a declarar
localmente, por ejemplo como un terminal no pasa nada, siempre tiene más
precedencia la declaración local.
Todos los símbolos declarados localmente en una gramática no interfieren en
otra gramática y se pueden volver a declarar. Ejemplo:.
grammar gram_1
{
terminal uno, dos;
}
grammar gram_2
{
/* esto no generea conflicto al ser gramáticas distintas */
terminal uno, dos;
}
Formato de las producciones
[ Inicio ]
Una producción tiene dos partes:
-
Parte izquierda:
En la parte izquierda sólo puede estar un no terminal.
-
Parte derecha: En la derecha se ponen listas de terminales y no
terminales. La estructura de dichos símbolos son simples identificadores o
caracteres. Los caracteres, como ya he dicho antes no hace falta declararlos en
la lista de terminales, ya que por defecto estos siempre son terminales. Para
poner la palabra vacía simplemente hay que dejar la parte derecha en blanco.
Además el símbolo '|' tiene el significado de la 'or'. Ejemplo:
grammar gramatica_de_prueba
{
nonterminal A, B, C;
terminal a, b, c;
// la parte derecha son dos terminales eguidos
// ademas como se puede ver he puesto el caracter +,
// y no hace falta declararlo.
A := a '+' b;
// si se deja en blanco entonces es la palabra vacia.
A := ;
// lo anterior también se podria haber puesto en una
// unica sentencia utilizando la or.
// A := a b | ;
}
Aspectos a destacar en la escritura de las producciones:
-
Como se puede ver al final de cualquier producción siempre termina con el
símbolo ';'.
-
La parte izquierda y derecha de una producción va separada por el símbolo ':='.
-
Los símbolos de la parte derecha de una producción se separan con espacios, si
se ponen dos identificadores seguidos, si entre medias se ponen un
carácter('+', '/', ...) no hace falta poner espacios. Por ejemplo: p := a'+'b
-
Con el símbolo '|' se consigue declarar varias producciones en una misma
expresión.
-
Si se deja en blanco la parte derecha de una producción significa la palabra
vacía
Antes de poder utilizar un símbolo en una producción hay que declararlo. Si se
quiere se pueden repetir producciones no se genera ningún conflicto. Ejemplo:
global
{
nonterminal A, B, C;
terminal a, b, c;
// esto es un grupo.
prods_globales =
{
A := a c | b;
B := a;
// no hace falta poner espacios, cuando se utilizan
// caracteres entrecomillados. Además como ya se ha comentado,
// no hace falta declarar el terminal '+'
B := a'+'b;
// no pasa nada simplemente se ignoran, y se dará un aviso.
B := a;
B := a;
B := a;
}
}
Sentencias específicas de la parte global
[ Inicio ]
Todo lo dicho anteriormente es válido para la parte global y para las
gramáticas locales. En la parte global además se pueden hacer declaraciones de
grupos de producciones. Estas sirven para agrupar producciones y se usan para
no repetir declaraciones de producciones si estas se van a utilizar en varias
gramáticas.
Estas declaraciones de grupo se colocan después de la parte de
declaraciones (análisis, terminales, no terminales). Cada sentencia de grupo
tiene un nombre y dentro se ponen las producciones que están dentro de dicha
sentencia de grupo.
Ejemplo de declaración de grupo:
global
{
nonterminal A, B, C;
terminal a, b, c;
// esto es un grupo, y esta compuesto por dos producciones.
prods_globales =
{
A := a c | b;
B := a;
}
}
Sentencias específicas de la parte local
[ Inicio ]
Las declaraciones de grupo no se pueden hacer en gramáticas locales, lo que si
se puede hacer es utilizar dichas declaraciones de grupo, además de declarar
producciones locales a la gramática en cuestión. Ejemplo:
global
{
nonterminal A, B, C;
terminal a, b, c;
// esto es un grupo.
prods_globales =
{
A := a c | b;
B := a;
}
}
grammar gramatica_local
{
nonterminal Uno, Dos;
terminal k1, k2, k3;
// ahora esta gramática incorpora las producciones
// del grupo prods_globales
prods_globales;
// pero también puede tener producciones locales.
Uno := k1 k2;
/*
* Como se puede ver en una producción local se pueden
* incorporar símbolos declarados localmente
* y símbolos declarados globalmente.
*/
Dos := k1 k2 a;
}
Definción léxica de tokens
Introducción
[ Inicio ]
Con el objetivo de facilitar la simulación de las gramáticas, se permite de manera opcional
la definición léxica de los tokens (terminales en las gramáticas).
Características del lenguaje de definiciones léxicas
[ Inicio ]
- Case sensitive: Se distinguen entre las letras mayúsculas y minúsculas.
- Sentencias: Es obligatorio acabar las sentencias en ';'. Entendiendose como sentencia la línea donde se está defiendo una expresión regular o
se utiliza la palabra reservada pass.
- Identificadores: Un identificador válido será cualquier secuencia de números, letras, símbolo '_' o combinación de estos elementos.
Los identificadores no pueden comenzar con un número y su longitud debe ser de uno como mínimo.
Ejemplos de identificadores válidos serían: id, id_, id1, a, _1,__id.
Identificadores no válidos: #id, [id], *id.
- Comentarios: Sólo se permiten comentarios de línea. La definición de un comentario comienza con "//".
Estructura de un archivo válido
[ Inicio ]
En un archivo un lexer se puede incluir y utilizar en la definición de una gramática. La definición de un lexer es opcional pero si se
hace es obligatorio que sea antes de la parte global o declaración de las gramáticas.
Ejemplo:
lexer lexer1
%{
...
%}
lexer lexer2
%{
...
%}
//definiciones de más lexers. Siempre antes de una definición global o gramatica.
...
global
{
...
}
grammar gramatica1
{
...
}
grammar gramatica2
{
...
}
Formato de una definición léxica
[ Inicio ]
La definición de un lexer se ajusta a la siguiente estructura:
lexer [identificador del lexer]
%{
tokens
{
[identificador token] := [expresion regular];
[identificador token] := [expresion regular];
...
}
pass [lista identificadores]; //opcional
%}
Donde cada elemento tiene el siguiente significado:
- lexer. Palabra reservada que indica el comienzo de una definición léxica.
- tokens. Palabra reservada necesaria para definir los tokens.
- pass. La utilización de pass es opcional y se usa cuando se
desea que ciertos tokens sean ignorado una vez reconocidos en la entrada (no se le pasan a el analizador sintáctico).
- [identificador del lexer]. Un identificador válido (globalLexer, lexerTest, etc.. ).
- [identificador token]. Un identificador valido (id, MAS, PARENTESIS, etc...).
- [expresion regular]. Descripción válida de una expresion regular (a+, a*, abc, etc).
- [lista identificadores]. Se puede definir un único identificador o varios separados por comas (Ejemplo:
pass id; o pass id1, id2, id3;).
Utilización de un lexer
[ Inicio ]
Para usar un lexer se debe utilizar la sintaxis:
use [identificador lexer] ;.
Se deben tener en cuenta las siguientes consideraciones cuando se utilize un lexer:
- Si se utiliza la sentencia analysis dentro de una gramática, use deberá estar situada detrás
de esta sentencia.
- Si se utiliza la sentencia nonterminal dentro de una gramática, use deberá estar situada delante
de esta sentencia.
- No esta permitido definir terminales dentro de la gramática donde se utiliza un lexer.
- No esta permitido usar un lexer dentro de un bloque de definiciones globales.
Un ejemplo de lo dicho anteriormente es el siguiente:
lexer globalLexer
%{
tokens
{
//definicion de los tokens.
}
%}
global
{
...
}
grammar gramatica_local
{
analysis LALR1;
use globalLexer;
nonterminal Uno, Dos;
...
}
grammar gramatica_local2
{
analysis LALR1;
use globalLexer;
...
}
grammar gramatica_local3
{
use globalLexer;
nonterminal Uno, Dos;
...
}
grammar gramatica_local4
{
use globalLexer;
...
}
Expresiones regulares válidas
[ Inicio ]
Una expresion regular válida se puede definir como:
- Un caracter simple: a , b, c, #, @, etc..
- Una cadena: "caracter+".
- Una clase: [ (caracter|rangos)+ ]
Los únicos rangos permitidos son:
- 0-9. Rango numérico ascendente o un subconjunto de éste (también ascendente).
- a-z. Rango de letrás ascendente o un subconjunto de éste (también ascendente).
- A-Z. Como en el caso anterior pero con létras mayúsculas.
- Una secuencia de escape: \r, \n, \t, \b, \f, \\, \" . Las secuencias de escape se pueden utilizar en cualquier parte de la
expresión regular excepto la secuencia \" que no esta permitida dentro de las cadenas.
- . : se reconoce un caracter simple. Esta definición no es aplicable dentro de una clase o cadena en las que se evalúa como el carácter punto.
Dentro de la definición de una expresión regular no se permiten el carácter de salto de línea(\n) o el de retorno de carro(\r).
Si a y b son dos expresiones regulares válidas están permitidas las siguientes operaciones:
- a b. La expresión regular resultante reconoce lo que reconozca a seguido de lo renocozca b (concatenación).
- a | b. La expresión regular resultante reconoce lo que reconozca a o lo que reconozca b (unión).
- a*. La expresión regular resultante reconoce cero o más ocurrencias de a. (clausura de Kleene).
- a+. Es equivalente a aa*.
- a?. Es opcional reconocer a.
- !a. Se reconoce todo aquello que no es reconocido por a.
- ( a ). Se reconoce lo que sea reconocido por a.
La forma en el que se resolverán los casos en los cuales varias expresiones regulares reconozcan la misma cadena de entrada
será por el orden de definición. La primera expresión regular definida tendrá prioridad sobre las demás.
Un ejemplo de definición y utilización completo de un lexer es el siguiente:
lexer calcLexer
%{
tokens
{
id := [a-zA-Z]+;
num := -?[0-9][0-9]*;
MAS := "+";
MENOS := "-";
POR := "*";
DIV := "/";
PAR_IZ := "(";
PAR_DE := ")";
nulos := [ \r\n\t];
}
pass nulos;
%}
grammar calc
{
analysis LALR1;
use calcLexer;
nonterminal E, T, F;
E := E MAS T | E MENOS T | T;
T := T POR F | T DIV F | F;
F := PAR_IZ E PAR_DE;
F := id | num;
}
AFDs asociados a la expresiones regulares
[ Inicio ]
Si se defíne un lexer y se compila la gramática, es posible ver
gráficamente los AFDs asociados a los tokens pulsando el botón
Ver AFDs.
Consideraciones en la escritura de la gramática
[ Inicio ]
Lo primero a destacar es que el símbolo inicial de la gramática es el no
terminal de la parte izquierda de la primera producción de la gramática.
Otro aspecto importante es conocer la forma en que en los análisis ascendentes
se generan los estados del autómata, ya que dos tablas de análisis pueden ser
equivalentes y no parecerlo porque se ha podido numerar de forma diferente los
estados que se han utilizado para generar dicha tabla. Para facilitar la
comprobación de ejercicios se va a seguir una convención única en la generación
del autómata de reconocimiento.
Los estados se van numerando en el orden natural, como si el análisis se
hiciera manualmente. Cuando se tiene un estado y se le van a calcular las
transiciones a otros estados los items dentro de dicho estados están ordenado
de la siguiente forma:
-
Primero los items que proceden de una transición desde otro estado. Si hay
varios, estos se ordenan por el orden en que la producción relacionada con el
item aparece en la gramática.
-
Después están los items calculados a partir del cierre de los items iniciales.
El orden en que se va calculando el cierre es desde la parte superior del
estado hasta la inferior. Los items con la misma parte izquierda calculados en
el cierre si hay varios se ordenan entre ellos por el orden en que aparece su
producción asicioada en la gramática.
Las transiciones se van calculando en el orden en que están puestos los items
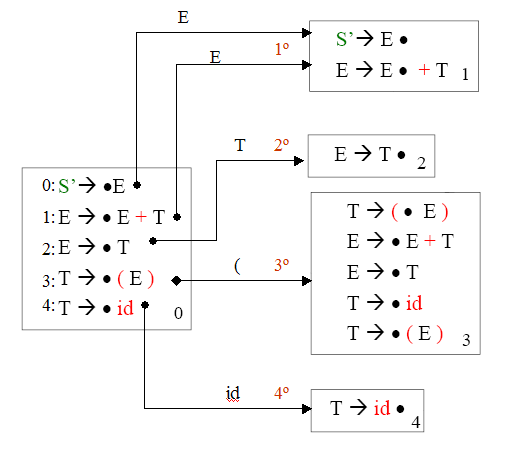
dentro del estado. Por ejemplo, si tuviéramos la siguiente gramática:
1: E =>
E + T 2: E =
> T 3: T
= > ( E ) 4:
T = > id
Parte del autómata que se generaría se puede ver en la siguiente figura.
Del estado 0 visto en la figura anterior podemos destacar lo siguiente:
-
El primer item del estado es el item por el que empezó el estado: "S' = > E".
-
Después están los items calculados por el cierre de dicho item.
-
Los items que tienen la misma parte izquierda , están ordenados por el orden en
que sus producciones fueron declaradas en la gramática. Si en la gramática se
hubiera puesto "E = > T" antes que "E = > E + T" entonces
en el estado el item "E = > T"
hubiera estado antes.
-
Los estados generados a partir del primer estado se van generando en el orden,
en que se va recorriendo sus items. Es decir, primero la transición del item "S'
= > E", después la del item "E = > T", ...
La forma en que se ha generado estos estados se repite con todos los estados.
En resumen la ordenación es como si el calculo del autómata se hiciera
manualmente, sabiendo la forma en que siempre el sistema genera los estados, si
nosotros al hacer los ejercicios manualmente los hacemos de esta forma, después
será más fácil comprobar los resultados de nuestros propios ejercicios.
Descripción del informe generado
Símbolos especiales
[ Inicio ]
En la generación del informe aparecen algunos símbolos especiales que no han
sido especificados en la gramática. El significado de los mismos es el
siguiente:
-
'@':
Es el símbolo elegido para identificar a la palabra vacía.
-
'$':
Es el símbolo final.
-
El símbolo que aparece con una ' (por ejemplo. S') al lado es el símbolo
inicial de la gramática extendida, para los análisis ascendentes
Mensajes de salida del compilador
[ Inicio ]
Aquí se muestran mensajes de salida generados desde el compilador. Estos pueden
ser de los siguientes:
Gramática
[ Inicio ]
Cuando se genera el informe se copia en dicho informe la gramática de la cual
proviene el análisis. El formato puede que no sea el mismo, porque las
producciones que se declaran con el símbolo '|', se separan y se pone una
debajo de la otra. Por ejemplo al escribir estas producciones:
Z := d | X Y Z;
Y := c | ;
X := Y | a;
En el informe las producciones, aparecerían sin el símbolo '|' y numeradas
según el orden de declaración.
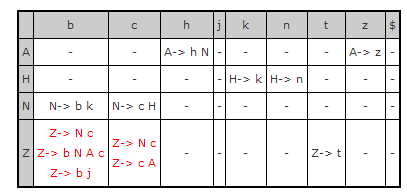
Conjunto de estados
[ Inicio ]
En el análisis ascendente el autómata se da de forma tabular. Donde cada
entrada de esta tabla representa un estado de autómata. Dentro del estado están
los items de dicho estado donde en estos items se da la siguiente
información (de izquierda a derecha):
-
Identificador de la producción.
-
Producción a partir de la cual se ha generado el item.
-
Marcador del item.
-
Símbolos de predicción encerrados entre llaves (si los tiene) .
-
Transición si es un desplazamiento, o la palabra reducir si es una reducción.
Un ejemplo, de autómata especificado en forma tabular se puede ver en la
siguiente figura.
Cuando se producen conflictos (ya sean LL1 o D/R, ...), estos se muestran en la
sección de salida del compilador, y en la tabla de análisis se marcan en rojo
las entradas conflictivas.
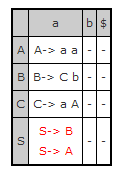
Tablas de análisis descendente.
[ Inicio ]
En las filas están los no terminales y en las columnas los terminales. La
cabecera de la tabla se ordena por orden alfabético, dejando al siempre al
final el símbolo '$'. En la tabla pueden haber dos elementos.
-
Producción:
Indica por la producción por la cual expandir.
-
Error: Indica que si se llega a esta configuración (fila y columnas de
esa entrada) hay un error. '-'
Un ejemplo de tabla de análisis LL(1) se puede ver en la siguiente figura.
La casilla que esta marcada en rojo es porque existe un conflicto LL(1). En
ella estan las producciones conflictivas. Este conflicto también se mostrará en
la parte de
Mensajes de salida del compilador
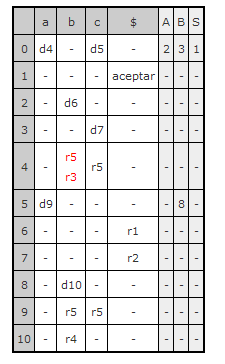
Tablas de análisis ascendente.
[ Inicio ]
Las columnas se dividen en dos partes (están sombreadas de color diferente), la
primera de ella es la tabla de acción y esta ordenada por orden alfabético. El
ultimo símbolo de la esta parte siempre es el símbolo final '$'. Un ejemplo, de
ello se puede ver en la siguiente figura.
La otra es la parte de Ir_A, y también esta ordenada por orden alfabético.
El significado de los símbolos dentro de la tabla son:
-
Desplazamientos: Van precedidos por la letra 'd'. Por ejemplo 'd5'.
-
Reducciones: Van precedidos por la letra 'r'. Por ejemplo 'r3'.
-
Transición de estados:
Estos están en la parte de la tabla de Ir_A.
-
Aceptación: Es el estado de aceptación y esta identificado con la
palabra 'aceptar'
-
Error: Entradas de la tabla para la que no hay definida una transición,
estas son las entradas con un símbolo '-'
Al igual que en la descendente si hay un conflicto, la casilla conflictiva se
marcará en rojo.
Información adicional
[ Inicio ]
Al generar las tablas de análisis siempre se genera información adicional, como
son la lista de seguidores, iniciales y anulables. Esta información es de gran
utilidad ya que facilita el encontrar errores y por ejemplo ver la causa de
conflictos.
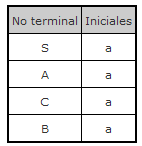
Un ejemplo de ello es esta gramática donde se produce un conflicto LL(1) y se
puede comprobar la causa de ello mirando la lista de iniciales.
S := A | B;
A := a a;
B := C b;
C := a A;
Al generar la tabla de análisis se genera un conflicto LL(1).
El conflicto indica que con una
'S' en la pila y una
'a' en la
entrada hay un conflicto. Y eso indica que los dos no terminales
'A' y
'B'
deben tener en sus iniciales el terminal
'a'. Esto se puede comprobar en
la tabla de iniciales.
Simulación
[ Inicio ]
Para simular desde el informe generado al compilar, hay que darle al botón
donde pone simular. Una vez estes en dicha ventana, sólo hay que escribir el
texto de entrada y darle a simular.
Otro aspecto a resaltar es el formato del texto de entrada a simular. Sólo se
puede introducir los terminales declarados en la gramática y los símbolos
especiales. Un ejemplo, con esta gramática:
grammar calc
{
analysis LALR1;
nonterminal E, T, F;
terminal id;
E := E '+' T | E '-' T | T;
T := T '*' F | T '/' F | F;
F := '(' E ')';
F := id;
}
Los únicos terminales permitidos son: id, +, -, /, (, ).
Por ejemplo un texto a simular podría ser el siguiente:
(id + id) / id
Como se puede ver aunque en la gramática el simbolo +, va entrecomillado,
cuando se introduce en el simulador estos símbolos no se ponen entre comillas.
Simulación paso a paso
[ Inicio ]
Para simular paso a paso desde el informe generado al compilar, primero hay que pulsar el
botón Simular Step. Se abrirá a continuación una ventana, en la que sólo hay que escribir
un texto de entrada y pulsar el botón simular.
Ejemplo de entorno de simulación para gramáticas LL1
En este entorno y utilizando los botones de simulación o el método abreviado podrá
simular paso a paso las gramáticas LL1.
Ejemplo de entorno de simulación para gramáticas SLR1, LR1, LALR1
En este entorno y por medio de los botones de simulación o método abreviado
se pueden simulan paso a paso las gramáticas SLR1, LR1, LALR1.
Botones de simulación
Los botones de simulación realizan las siguientes acciones:
-
Botón prev: Decrementa el índice de simulación de la tabla pila/entrada en una unidad.
-
Botón next: Avanza el índice de simulación de la tabla pila/entrada en una unidad.
-
Botón reset: El índice de simulación, se posiciona en la entrada cero de tabla pila/entrada.
Con esta acción, la simulación se lleva al estado inicial.
-
Botón end: El indice de simulación, se posiciona en la última entrada de la tabla pila/entrada.
Mediante esta acción se comprueba si la cadena es aceptada.
-
Botón Arbol sintatico: Pulsando una vez el botón se muestra el árbol sintáctico
correspondiente al estado actual de la simulación. Si se quiere ocultar el arbol,
bastará con pulsar de nuevo el botón.
Los botones prev, next, reset y end, actualizan
el estado de todas las tablas de simulación y el arból sintáctico (si se esta visualizando)
Para finalizar, introduciendo un número y pulsando enter en la caja de texto Ir a
el índice de simulación se posicionaría en la entrada especificada de la tabla pila/entrada.
Teclas de acceso rápido
Con el objeto de facilitar el proceso de simulación, se han definido métodos abreviados
de teclado. Los métodos abreviados se clásifican según el navegador
que se este utilizando:
Firefox
-
ALT-SHIFT-B: Botón prev.
-
ALT-SHIFT-N: Botón next.
-
ALT-SHIFT-,: Botón reset.
-
ALT-SHIFT-.: Botón end.
-
ALT-SHIFT-M: Árbol Sintáctico.
-
ALT-SHIFT-G: Ir entrada.
Internet Explorer
-
ALT-B: Botón prev.
-
ALT-N: Botón next.
-
ALT-,: Botón reset.
-
ALT-.: Botón end.
-
ALT-M: Árbol Sintáctico.
-
ALT-G: Ir entrada.
Herramientas utilizadas
[ Inicio ]
Tecnologías utilizadas en PROLETOOL:
-
Construcción del compilador:
-
Lenguaje de programación: Java
-
Entorno de desarrollo para programar en java Eclipse
-
Para la construcción del analizdor léxico se ha utilizado
JFlex.
-
El analizador sintáctico se ha creado con
CUP.
-
La base de datos está construida sobre el sistema de gestión de bases de datos
PostgreSQL.
-
La web se ha creado utilizando el lenguaje Python.
-
Los gráficos se han generado con Graphviz.
-
El traductor de expresiones regulares se ha construido utilizando dk.brics.automaton.
-
Para el sistema de mensajes de logs en el compilador se utilizando log4j.
-
Para el sistema de pruebas del compilador se ha utilizado JUnit.